100 Days of Gen AI: Day 12
My training job finished! I had to leave it running all day yesterday. It took nearly 13 hours to complete running on my 2017 Macbook Pro (definitely non-ideal hardware for training tasks).
Here’s my trained model!
Here are my logs:
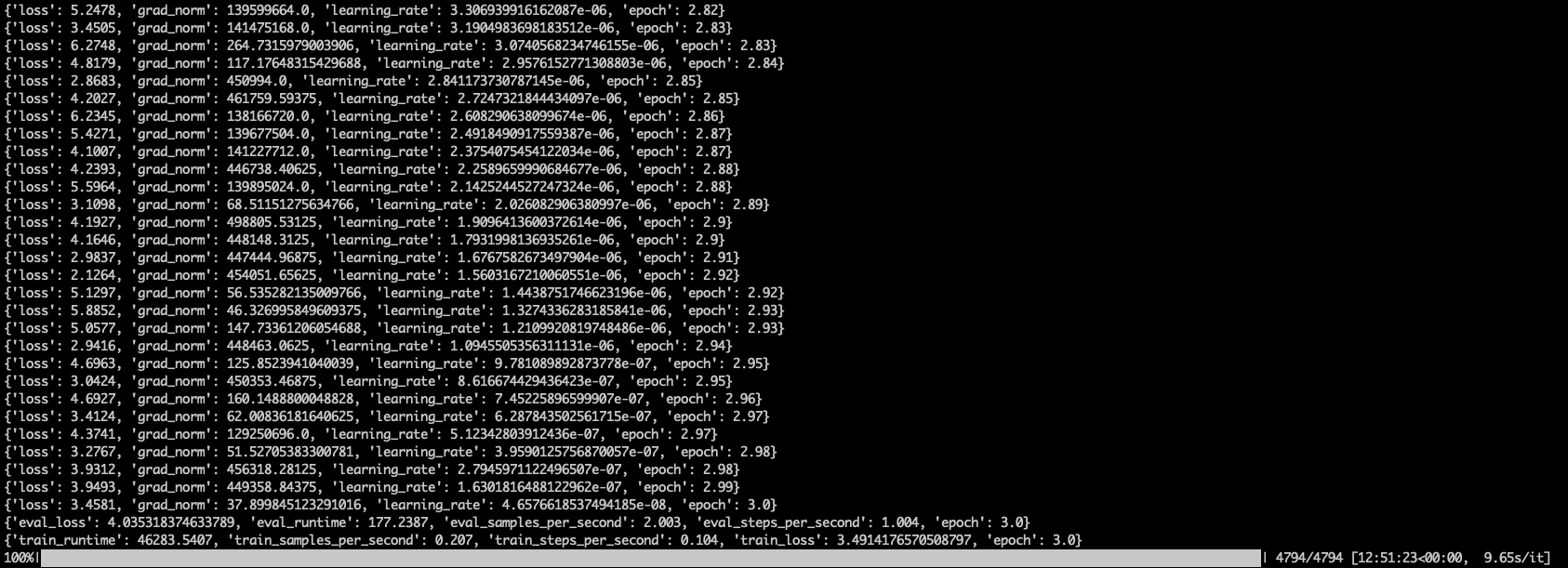
The training loss (3.49) and validation loss (4.03) are relatively close, which is a good sign that the model isn’t overfitting too much. However, the loss values themselves are still somewhat high, suggesting the model may need further fine-tuning or more data to reach better performance. This is somewhat expected as the dataset I used is of dubious quality.
The fine_tuned_model directory is 500MB, and the results folder is 4.5GB.
To the question:
What is the meaning of life?
It responded with:
SOC.,?
It’s something! Though not very intelligible. It looks like I’ve only made this model dumber than the GPT-2 model I started with. :)
There are several steps I could try to improve my model, such as:
- Adjust the learning rate to something smaller, such as 1e-5 or 1e-6.
- Mix the dataset with a general text dataset like OpenWebText or WikiText to keep GPT-2’s general knowledge intact.
- Freeze some layers of GPT-2 to retain general language capabilities.
- Use larger GPT-2 models (medium, large) or GPT-3, if available.
- Train for more epochs since my dataset is kinda small.
However I’m not super keen to retrain a model when the feedback loop is ~13 hours. Obviously, the proper way to compress this time would be to train the model in the cloud, but that would require me to pay actual MONEY, and I’m just trying to learn right now. And at its core I think the dataset I started with is not of sufficient quality to train a model. Without a good dataset, I think it’s time to move on from this Socrates chatbot project.
I could pivot to training a model with a better quality public dataset (design the project around the dataset), or I could try creating my own small dataset and train on that. Since I’m more interested in building models with my own custom datasets, I think the latter makes sense.